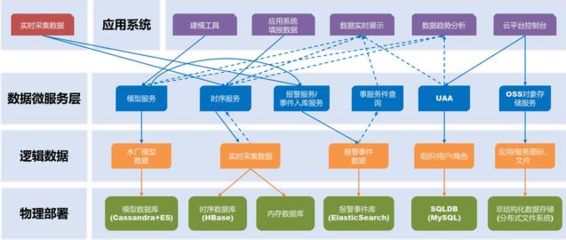
在數字化浪潮席卷全球的今天,“數據驅動力”已成為企業乃至國家競爭力的核心要素。強大的數據驅動力,意味著能夠高效地從海量數據中提煉洞察、指導決策、驅動創新。這股力量的源泉和基石,正是穩健、高效、智能的數據處理與存儲服務。提升數據驅動力,不能僅僅停留在應用和分析層面,更需從底層服務架構入手。本文將聚焦于數據處理與存儲服務,探討提升數據驅動力的三個關鍵層面。
第一層面:基礎架構層——構建堅實、彈性、融合的存儲與計算底座
這是數據驅動力的“物理基礎”。提升驅動力,首先要確保數據能夠被安全、可靠、低成本地存下來,并能被高效地計算和處理。
- 存儲服務的進化:從傳統的本地磁盤、SAN/NAS,到分布式對象存儲、云原生存儲,存儲服務正朝著海量化、高持久性、高擴展性和極低成本的方向發展。采用混合云或多云存儲策略,可以實現數據在本地與云端的靈活流動與備份,滿足不同熱度數據(熱、溫、冷、冰)的存儲需求與成本優化。提升此層面的驅動力,關鍵在于選擇或構建與業務數據增長模式、訪問模式相匹配的存儲架構,實現存力的彈性伸縮。
- 處理能力的升級:數據處理服務已超越傳統的批處理(如Hadoop),進入流批一體、實時化時代。云原生數據倉庫、湖倉一體(Lakehouse)架構、以及基于Kubernetes的彈性計算框架,使得數據處理資源能夠隨需而動,秒級擴展。提升點在于構建統一的數據處理平臺,減少數據移動,支持從實時風控到離線報表的多樣化計算負載,讓數據“算得快、算得省”。
- 存算關系的重構:“存算分離”已成為主流范式。它將存儲與計算資源解耦,允許各自獨立擴展,避免了傳統存算一體架構中因資源綁定帶來的浪費與瓶頸。通過高速網絡(如RDMA)連接存算節點,在獲得彈性優勢的保障了數據處理性能。提升此層面的驅動力,意味著積極擁抱存算分離架構,實現資源利用效率的最大化。
第二層面:數據管理層——實現數據資產化、質量化與安全可控
當數據被存儲和計算后,如何將其管理成可信、可用、有價值的資產,是激活數據驅動力的核心環節。
- 元數據與數據目錄:建立企業級的數據地圖(Data Catalog),自動采集技術、業務、操作元數據。這能解決“數據在哪里、是什么、誰負責、怎么用”的問題,極大提升數據發現和理解效率,是數據自助分析服務的基礎。提升數據治理的透明度和自動化水平是關鍵。
- 數據質量與生命周期管理:通過內置數據質量檢核規則(準確性、完整性、一致性、時效性等)的服務,在數據入庫、處理環節進行監控與告警。制定清晰的數據生命周期策略,從采集、存儲、歸檔到銷毀,實現全鏈路管理,在合規前提下優化存儲成本。提升點在于將質量管控嵌入數據處理流水線(Data Pipeline),變事后檢查為事中攔截。
- 數據安全與隱私保護:數據處理與存儲服務必須內置強大的安全能力,包括但不限于:靜態加密、傳輸加密、細粒度的訪問控制(基于角色或屬性的RBAC/ABAC)、數據脫敏、審計追蹤以及符合GDPR、CCPA等法規的隱私計算技術(如聯邦學習、安全多方計算)。提升此層面的驅動力,意味著構建“默認安全”的數據基礎設施,筑牢信任基石。
第三層面:服務與賦能層——提供敏捷、智能、普惠的數據服務
最上層直接面向數據消費者(數據分析師、科學家、業務人員、應用系統),目標是降低數據使用門檻,讓數據能力像水電一樣隨取隨用。
- 自助式數據服務平臺:提供統一的數據查詢、探索、申請和交付服務門戶。用戶可以通過SQL或低代碼界面,便捷地訪問已認證的數據資產,獲取所需數據集或API,無需深諳底層技術細節。提升點在于打造極佳的用戶體驗和高效的服務流程。
- 智能化數據處理服務:將AI能力注入數據處理流程。例如,利用機器學習自動進行數據分類、打標、異常檢測、關聯推薦;智能優化數據存儲布局與查詢執行計劃;甚至自動生成數據摘要與可視化圖表。這能顯著提升數據處理效率與洞察發現速度。
- API化與微服務化:將核心的數據處理能力(如數據清洗、特征工程、模型預測)封裝成標準的API或微服務。這使業務應用能夠以松耦合的方式靈活調用數據能力,快速構建數據驅動的智能應用,加速業務創新閉環。
提升數據驅動力是一個系統工程,而數據處理與存儲服務是其堅實底座。從基礎架構層的彈性融合,到數據管理層的資產化治理,再到服務賦能層的敏捷智能,這三個層面層層遞進,相互支撐。企業應系統性地在這三個層面持續投入和優化,將數據處理與存儲從成本中心轉化為價值引擎,從而真正釋放數據的磅礴動能,在數字化競爭中贏得先機。