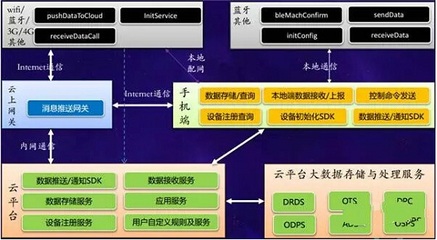
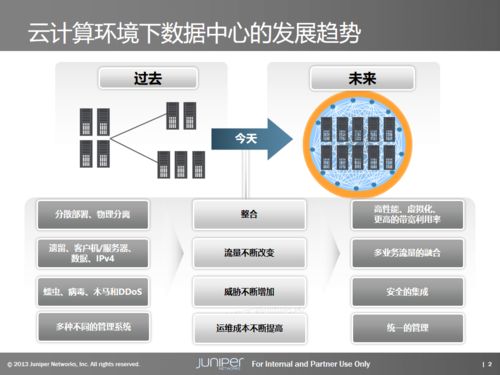
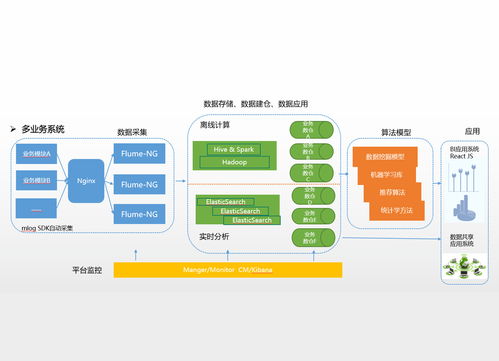
隨著容器化和微服務架構的廣泛應用,Kubernetes已成為云原生應用部署和管理的事實標準。在Kubernetes環境中,日志作為系統運行狀態、應用行為和故障排查的重要依據,其采集、存儲與處理顯得尤為重要。本文將探討Kubernetes下日志采集、存儲與處理的技術實踐,重點介紹數據處理和存儲服務的實現方案。
一、日志采集技術實踐
在Kubernetes中,日志采集面臨容器動態調度、多副本部署等挑戰。常見的采集方式包括:
- Sidecar模式:通過為每個Pod添加一個日志采集容器(如Fluentd、Filebeat),將應用日志輸出到共享卷,再由Sidecar容器讀取并發送至日志存儲系統。
- DaemonSet模式:在集群每個節點部署日志采集代理(如Fluent Bit、Logstash),采集節點上所有容器的日志文件。
- 應用直接推送:應用通過SDK或API直接將日志發送到日志服務(如日志服務商或自建服務)。
實踐中,DaemonSet模式因資源消耗低、部署簡單而廣泛使用,而Sidecar模式適用于多租戶或日志格式復雜的場景。
二、日志存儲服務方案
日志存儲需考慮可擴展性、持久性和查詢性能。主流方案包括:
- 集中式日志存儲:使用Elasticsearch、Loki等作為日志存儲后端。Elasticsearch支持全文檢索和復雜分析,適合大規模日志;Loki基于標簽索引,存儲效率高,與Grafana集成良好。
- 對象存儲:將日志歸檔至云服務商的對象存儲(如AWS S3、阿里云OSS)或自建MinIO,適用于冷數據存儲,成本較低。
- 時序數據庫:若日志含時間序列數據(如指標日志),可選用InfluxDB或Prometheus,支持高效時間范圍查詢。
存儲方案選擇需結合日志量、查詢需求和成本。例如,熱數據存Elasticsearch,冷數據轉存對象存儲。
三、數據處理服務實踐
日志處理包括解析、過濾、富化和轉發,常見工具如下:
- 流處理引擎:使用Flink或Kafka Streams對日志流進行實時處理,如提取關鍵字段、異常檢測。
- 日志處理代理:Fluentd或Logstash支持插件化處理,可解析JSON、正則匹配、添加元數據(如Pod標簽)。
- 服務網格集成:通過Istio等服務網格采集網絡日志,并結合Envoy Access Log進行流量分析。
數據處理環節可結合Kubernetes元數據(如Pod名稱、命名空間)富化日志,提升可觀測性。例如,Fluentd通過Kubernetes Metadata Filter插件自動添加Pod信息。
四、完整架構示例
一個典型的Kubernetes日志流水線包括:
- 采集層:DaemonSet部署Fluent Bit,采集節點日志并初步過濾。
- 處理層:日志發送至Kafka消息隊列,由Flink消費并進行實時解析。
- 存儲層:處理后的日志存入Elasticsearch,供Kibana可視化;同時歸檔至S3。
- 告警與監控:通過Elasticsearch Alerting或Prometheus檢測日志異常,觸發告警。
五、最佳實踐與挑戰
- 資源管理:為日志采集組件設置資源限制,避免影響應用性能。
- 日志旋轉與保留:配置日志文件大小和保留策略,防止磁盤溢出。
- 安全與合規:加密日志傳輸(TLS/SSL),實施訪問控制,滿足審計要求。
- 多云與混合云:使用統一日志格式和采集標準,便于跨環境管理。
Kubernetes下的日志技術實踐需結合采集、存儲與處理,形成端到端的流水線。通過選擇合適的工具和架構,可實現高效、可靠的日志管理,為運維和開發提供強大支持。