在數字化娛樂浪潮中,Netflix憑借其卓越的數據處理能力,不僅重塑了用戶收視習慣,更重新定義了內容產業的運作模式。通過不斷演進的數據處理架構,Netflix成功將海量用戶數據轉化為精準的收視率預測和個性化推薦,實現了從內容平臺到數據驅動型企業的華麗轉型。
第一階段:云端遷移與基礎架構建設
Netflix早在2008年就開始向亞馬遜云服務(AWS)全面遷移,這一戰略決策為其后續的數據處理能力奠定了堅實基礎。通過利用AWS的彈性計算和存儲資源,Netflix建立了可擴展的數據管道,能夠處理每日產生的數PB級別用戶行為數據,包括播放記錄、搜索查詢、評分和觀看時長等多元信息。
第二階段:實時流處理系統的構建
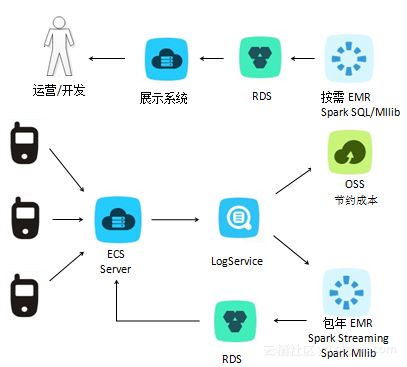
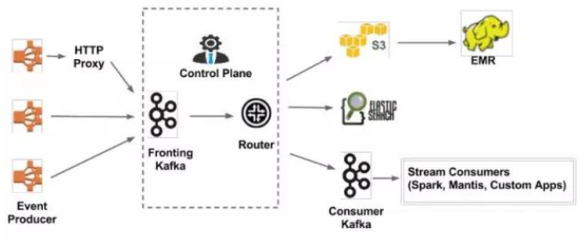
隨著用戶規模急劇擴張,Netflix開發了名為"Keystone"的實時數據流處理平臺。該系統基于Apache Kafka和Apache Samza構建,能夠實時處理每秒數百萬條事件數據。這種實時處理能力使得Netflix可以在用戶觀看過程中即時調整推薦算法,實現真正的動態個性化體驗。
第三階段:機器學習與深度學習集成
Netflix將機器學習深度整合到數據處理流程中,開發了專門的機器學習基礎設施"Metaflow"。這個平臺支持從數據預處理、特征工程到模型訓練和部署的全流程管理。通過分析用戶觀看模式、設備類型、地理位置等數百個特征維度,Netflix的推薦系統能夠精準預測用戶的收視偏好,顯著提升用戶粘性和內容消費時長。
第四階段:多云架構與數據治理
為確保數據處理的高可用性和合規性,Netflix采用了多云戰略,在AWS基礎上引入了Google Cloud Platform。同時建立了完善的數據治理框架,包括數據質量監控、隱私保護機制和合規性檢查,確保在滿足全球各地數據法規要求的持續優化數據處理效能。
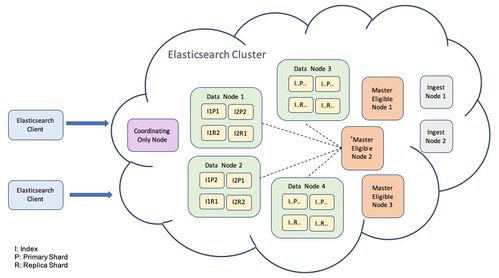
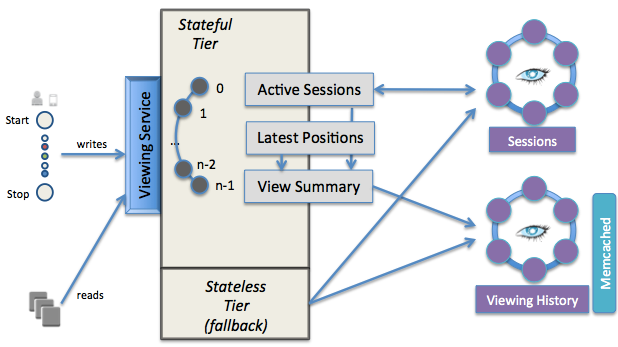
存儲服務的演進:從單一到分層
在數據存儲方面,Netflix經歷了從關系型數據庫到多層級存儲體系的轉變。當前架構包括:
- 實時緩存層:使用Memcached和EVCache支持毫秒級響應
- 在線存儲層:采用Cassandra和DynamoDB處理結構化數據
- 離線存儲層:利用S3和HDFS存儲歷史數據供批處理分析
- 數據倉庫:基于Iceberg和Presto構建企業級數據湖
數據處理服務的創新實踐
Netflix開創性地將數據處理服務產品化,內部團隊可以像使用公共服務一樣調用數據處理能力。通過"Genie"作業調度系統和"Mantis"實時流處理框架,實現了數據處理任務的標準化和自動化管理。這種服務化架構大大降低了數據使用的技術門檻,使得產品團隊能夠快速實驗和迭代新的推薦算法。
效果與影響
這套不斷演進的數據處理架構為Netflix帶來了顯著的業務價值:
- 用戶參與度提升:個性化推薦貢獻了超過80%的觀看內容
- 內容投資優化:通過收視預測模型顯著提高了原創內容成功率
- 運營效率提升:自動化數據處理流程減少了70%的人工干預
- 全球化擴展:支持在190多個國家提供本地化服務
Netflix繼續在邊緣計算、聯邦學習和隱私增強技術等領域進行探索,致力于在保護用戶隱私的進一步提升數據處理和個性化服務的能力。這種以數據為核心的架構演進,不僅鞏固了Netflix在流媒體領域的領先地位,更為整個行業樹立了數據處理架構演進的典范。