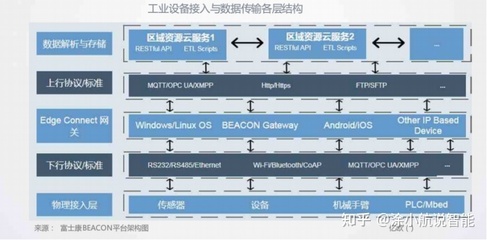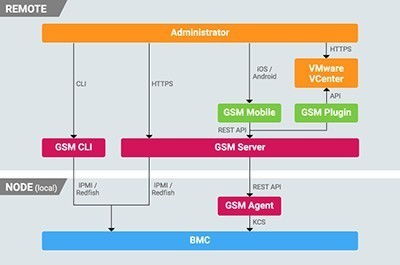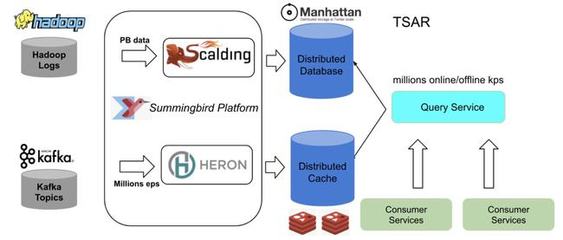
隨著數據規模的指數級增長,Twitter在數據處理和存儲服務方面面臨諸多挑戰。為提升系統效率、可擴展性和實時性,Twitter決定棄用原有的Lambda架構,轉向基于Kafka和現代數據流技術的新架構。這一轉變不僅優化了數據處理流程,還為存儲服務帶來了顯著的性能提升。
Lambda架構雖然在過去為Twitter提供了批處理和實時處理的結合方案,但其復雜性高、維護成本大,且難以適應快速變化的數據需求。例如,Lambda需要維護兩套獨立的代碼庫和基礎設施,導致數據處理延遲和系統資源浪費。因此,Twitter選擇棄用Lambda,以實現更簡潔、高效的架構設計。
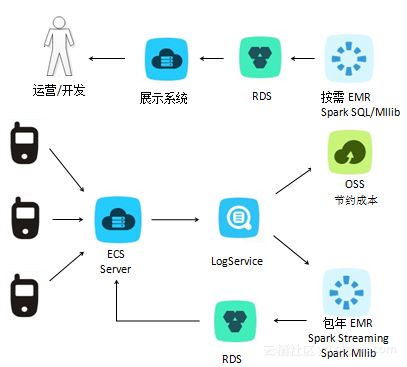
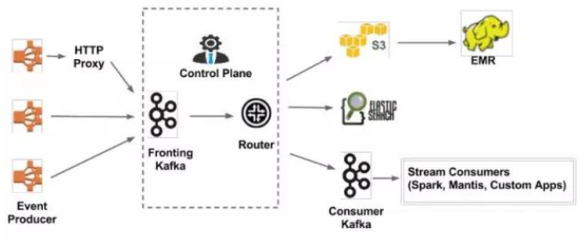
新架構的核心組件是Kafka,一個分布式的事件流平臺。Kafka以其高吞吐量、低延遲和可擴展性著稱,能夠處理Twitter海量的實時數據流。通過Kafka,Twitter可以輕松地捕獲、存儲和傳輸數據,例如用戶推文、互動事件和系統日志,從而為下游應用提供一致的數據源。這不僅簡化了數據管道,還減少了數據冗余和錯誤。
Twitter還集成了其他數據流技術,如Apache Flink或Apache Samza,用于實時數據處理和分析。這些工具允許Twitter在數據流入時進行復雜的轉換、聚合和過濾,無需依賴批處理延遲。例如,實時監控用戶行為、檢測異常活動或生成動態推薦,都得益于這種數據流架構的即時響應能力。
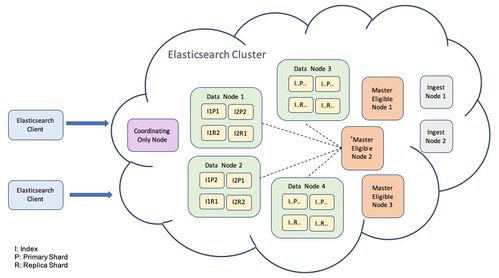
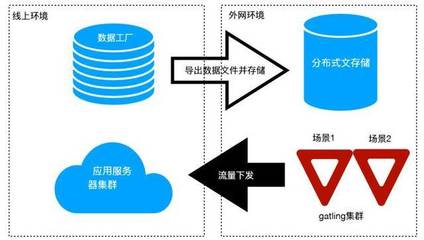
在存儲服務方面,新架構結合了分布式數據庫和云存儲解決方案,提升了數據的可靠性和訪問速度。通過將數據流與存儲層緊密集成,Twitter能夠實現更高效的數據持久化、備份和檢索,支持高并發查詢和機器學習應用。這種架構還增強了系統的容錯性,確保在節點故障時數據不會丟失。
Twitter的這一架構轉型標志著其數據處理與存儲服務的現代化進程。通過棄用Lambda并啟用Kafka和數據流新架構,Twitter不僅降低了運維成本,還提升了用戶體驗,為未來大數據和AI驅動的創新奠定了堅實基礎。隨著技術的不斷演進,這一舉措有望成為行業標桿,激勵更多企業優化其數據處理策略。