隨著工業自動化與信息化深度融合,力控產品在智能制造、能源管理、安全監測等領域的應用日益廣泛。面對海量數據和高并發處理需求,傳統集中式架構已難以滿足實時性、可靠性和擴展性要求。本文提出一種基于分布式架構的力控產品應用方案,重點闡述數據處理與存儲服務的實現路徑與優勢。
一、分布式架構的核心價值
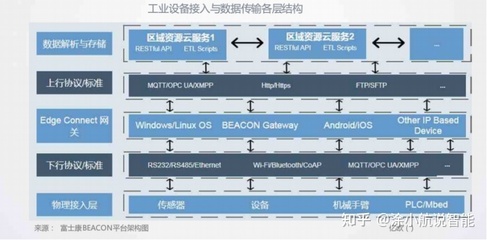
分布式架構通過將系統功能模塊分散部署于多個節點,實現了資源的高效利用與負載均衡。在力控產品應用中,該架構能夠有效應對數據采集點分散、處理實時性要求高、系統容錯需求強等挑戰。借助微服務設計與容器化技術,各數據處理與存儲模塊可獨立開發、部署與擴展,提升了系統的靈活性與維護效率。
二、數據處理服務的設計與實現
數據處理作為力控系統的核心環節,需確保實時性與準確性。本方案采用流處理與批處理相結合的方式:
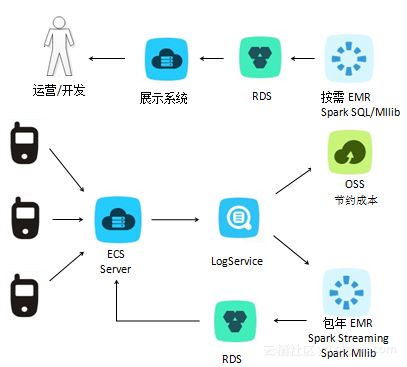
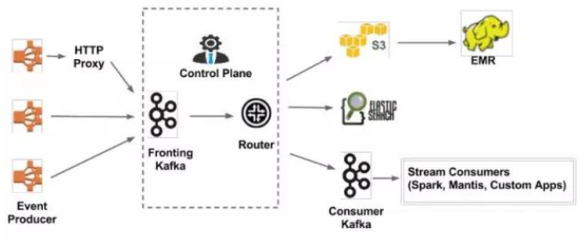
- 實時流處理:通過分布式消息隊列(如Kafka)接收傳感器數據,利用流計算引擎(如Flink)進行實時濾波、異常檢測與特征提取,確保毫秒級響應。
- 批量分析:對歷史數據采用分布式計算框架(如Spark)進行深度挖掘,支持模式識別、趨勢預測與優化決策。
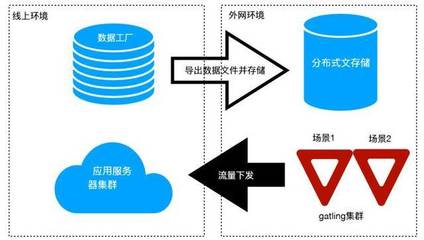
- 邊緣計算協同:在靠近數據源的邊緣節點部署輕量級處理模塊,實現數據本地預處理,減輕中心系統負擔。
三、數據存儲服務的架構優化
為滿足力控產品對數據持久化、查詢效率與安全性的多元需求,存儲服務采用多層次設計:
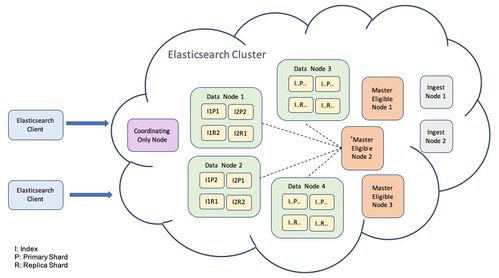
- 實時庫與歷史庫分離:使用時序數據庫(如InfluxDB)存儲實時監測數據,支持高頻讀寫;利用分布式列式數據庫(如HBase)歸檔歷史數據,保障長期存儲與快速檢索。
- 多副本與容災機制:通過分布式文件系統(如HDFS)或對象存儲實現數據冗余備份,結合一致性協議(如Raft)確保數據安全與系統高可用。
- 統一數據服務接口:提供RESTful API與SQL查詢接口,屏蔽底層存儲差異,便于上層應用集成與數據分析。
四、應用場景與效益分析
本方案已成功應用于智能電網力控監測、工業機器人力矩管理、油氣管道壓力監控等場景。實踐表明,分布式架構下的數據處理與存儲服務能夠:
- 提升系統吞吐量50%以上,支持千萬級數據點并發處理;
- 降低單點故障風險,實現99.99%服務可用性;
- 通過彈性擴展降低硬件成本,適應業務快速增長需求。
五、未來展望
隨著5G、人工智能與邊緣計算技術的發展,力控產品應用將進一步向智能化、自適應演進。未來,我們計劃引入聯邦學習機制,在分布式節點間協同訓練模型,提升系統智能決策能力;同時探索區塊鏈技術在數據溯源與安全審計中的應用,構建可信工業數據生態。
結語
分布式架構為力控產品提供了堅實的技術底座,通過精細化設計的數據處理與存儲服務,有效解決了大規模應用中的性能、可靠性與擴展性難題。這一方案不僅適用于現有工業場景,也為未來智慧工廠、數字孿生等創新應用奠定了堅實基礎。